다중회귀란?
여러개의 특성을 사용한 선형회귀(1차만 선형이 아님!)를 다중회귀라고 한다.
1개의 특성을 사용하면 학습하는것은 직선.. 2개의 특성을 사용하여 학습하면 평면.. 3개 이상부터는 어떻게 되는가?
-> 기존 특성들을 이용하여 새로운 특성을 만들어 사용한다 => 이를 특성공학이라고 함
사이킷런의 변환기(Transformer)
사이킷런은 특성을 만들거나 전처리하기 위한 다양한 클래스를 제공한다. 변환기 클래스는 모두 fit(), transform()메소드를 제공한다.
PolynomialFeatures : 사이킷런의 변환기중 하나이며 sklearn.pre
processing 라이브러리에 포함되어 있다. 입력데이터의 다항식 특성을 생성하도록 해주며 선형 모델이 비선형 특성을 잘 포착할 수 있도록 할 수 있다.
사이킷런 홈페이지에서 레퍼런스를 확인할 수 있다. degree = 2일 때 아래와 같이 [1,a,b,a^2,ab,b^2]를 반환하는 것을 볼 수 있다. (1은 선형 방정식의 절편. 절편은 항상 1과 곱해진다고 볼 수 있음, 디폴드 degree값은 2)
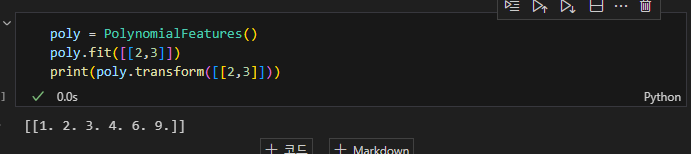
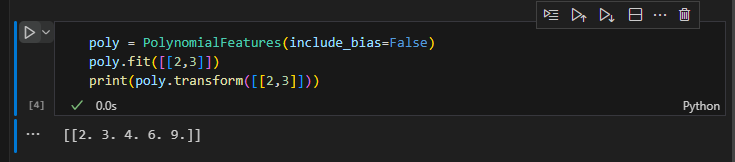
transformer를 이용하여 학습과 평가를 진행하여 봄
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
df = pd.read_csv('https://bit.ly/perch_csv_data')
perch_full = df.to_numpy()
print(perch_full)
train_input, test_input, train_target, test_target = train_test_split(perch_full, perch_weight,random_state=42)
poly = PolynomialFeatures(include_bias=False)
poly.fit(train_input)
train_poly = poly.transform(train_input)
print(train_poly.shape)
print(poly.get_feature_names_out())
test_poly = poly.transform(test_input)
lr = LinearRegression()
lr.fit(train_poly,train_target)
print('train set score : ',lr.score(train_poly,train_target)) #99
print('test set score : ',lr.score(test_poly, test_target)) #97
## degree를 높이면 과적합 문제 발생
++특성의 스케일을 고려해야 한다. -> 평균과 표준편차를 사용한 표준점수화. / StandardScaler를 사용할 수 있음
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_poly)
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)과적합을 방지하기 위하여 '규제'를 해준다. 선형 회귀 모델의 경우 특성에 곱해지는 계수의 크기를 작게 만들어 준다.
-> 선형 회귀 모델에 규제를 추가한 모델을 Ridge(릿지) Lasso(라쏘)라고 한다.
릿지는 계수를 제곱한 값을 기준으로 규제를 적용하고 라쏘는 계수의 절댓값을 기준으로 규제를 적용.(일반적으로 릿지 사용)
from sklearn.linear_model import Ridge
ridge = Ridge()
ridge.fit(train_scaled,train_target)
print('train set score',ridge.score(train_scaled, train_target))
print('test set score',ridge.score(test_scaled, test_target) )
## 과대적합되지 않은 것을 확인할 수 있음Ridge는 하이퍼파라미터 alpha 값으로 규제의 정도를 정할 수 있는데 적절한 alpha값을 찾는 방법은 알파값에 대한 스코어를 구하여 적합한 알파값을 알아볼 수 있다.
import matplotlib.pyplot as plt
train_score = []
test_score = []
alpha_list = [0.001,0.01,0.1,1,10,100]
for a in alpha_list:
ridge = Ridge(alpha=a)
ridge.fit(train_scaled,train_target)
train_score.append(ridge.score(train_scaled,train_target))
test_score.append(ridge.score(test_scaled,test_target))
plt.plot(np.log10(alpha_list),train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.show()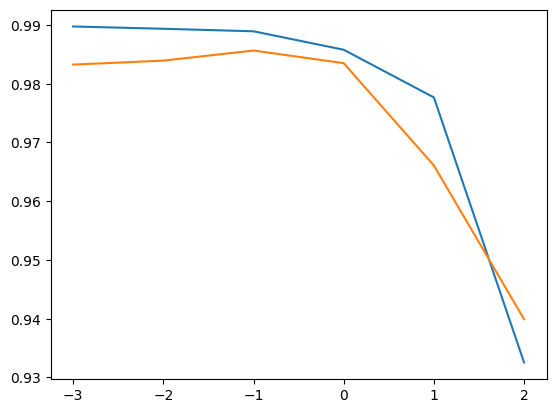
Lasso 모델도 마찬가지로 적당한 알파값을 사용하면 과소적합, 과대적합을 피할 수 있음을 확인해볼 수 있다.
'ML' 카테고리의 다른 글
| ML4 확률적 경사 하강법8 (0) | 2024.08.07 |
|---|---|
| 2-1 (0) | 2024.01.29 |
| ML 1-3 (2) | 2024.01.28 |


