대-AI 시대가 도래함에 따라 기초적인 AI 지식 정도는 찍먹해 줘야 한다고 생각하여 공부를 시작
ML에 포스팅되는 대부분의 포스팅은 <혼자 공부하는 머신러닝+딥러닝(한빛미디어)> 교재를 통해 공부한 내용일 것입니다.
K - Nearest Neighborhodd(K-NN) 알고리즘
*구글 Colab은 파이썬을 기반으로 작동한다.
생선의 종류를 구분하는 경우를 K-NN으로 구현해보기.
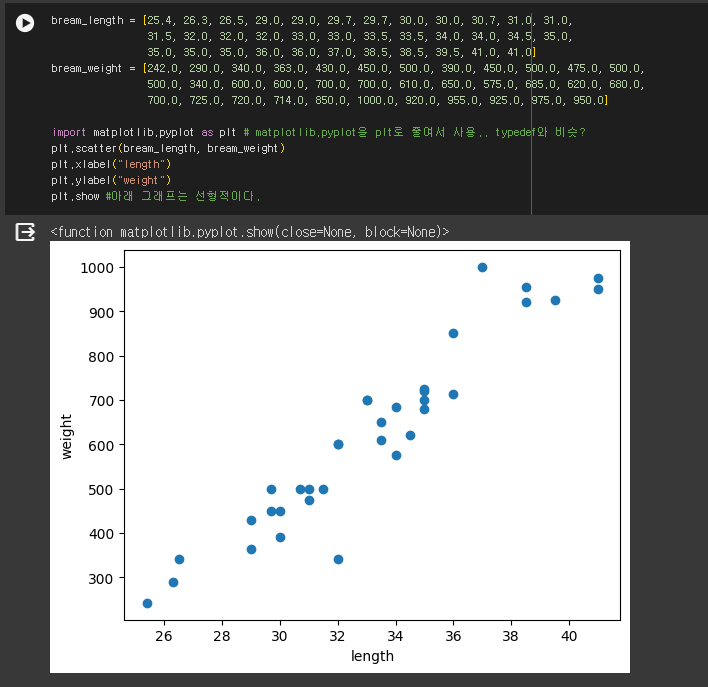
- 라이브러리 추가 import 사용
- as ~ : C에서 typedef와 비슷하다.
- 그래프를 점선도로 plot하기 : .stcatter
- .show를 통해 표시.
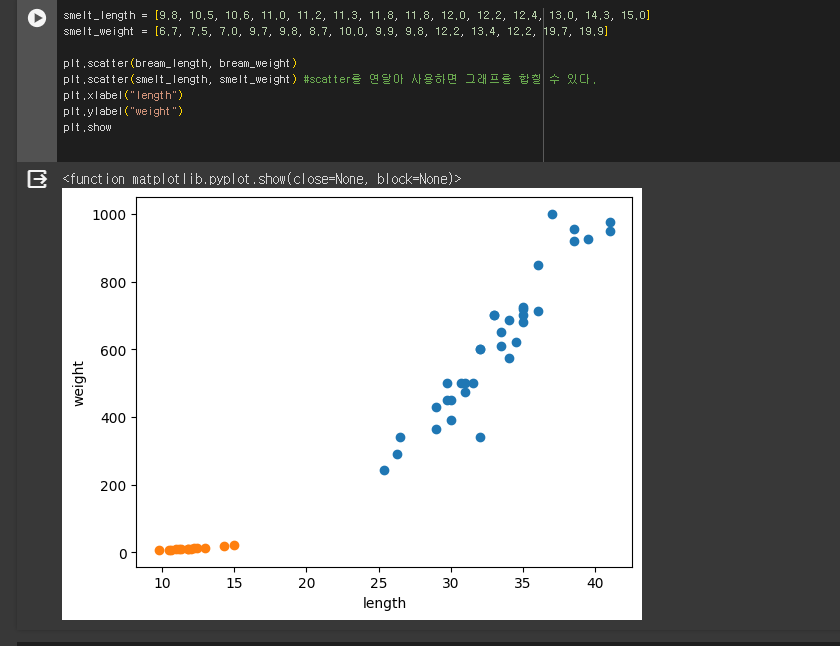
scatter를 합치면 한번에 표시 가능하다
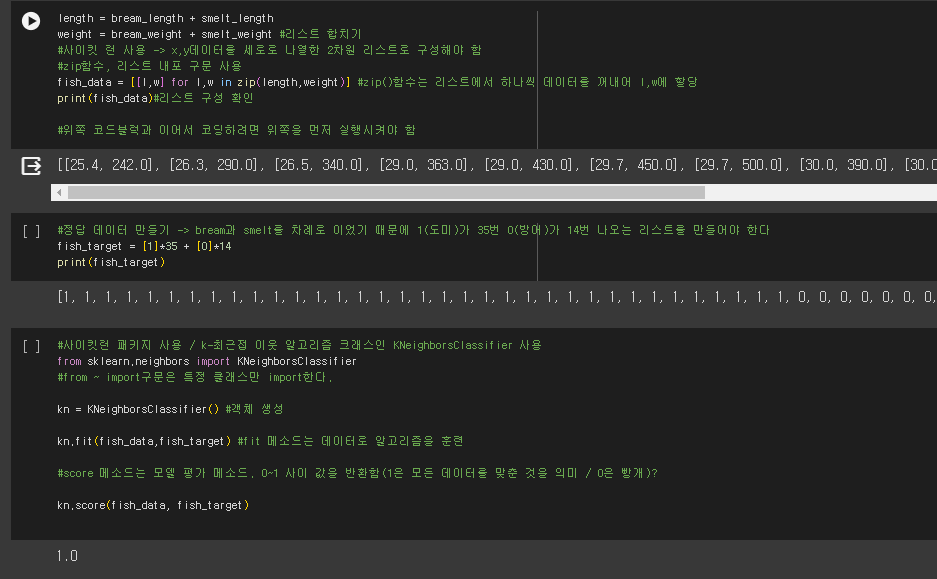
- K-NN알고리즘은 정답 데이터를 K-NN객체 안에 넣어 데이터를 통해 들어오는 입력값을 판단한다.
- score함수는 성능평가에 사용.
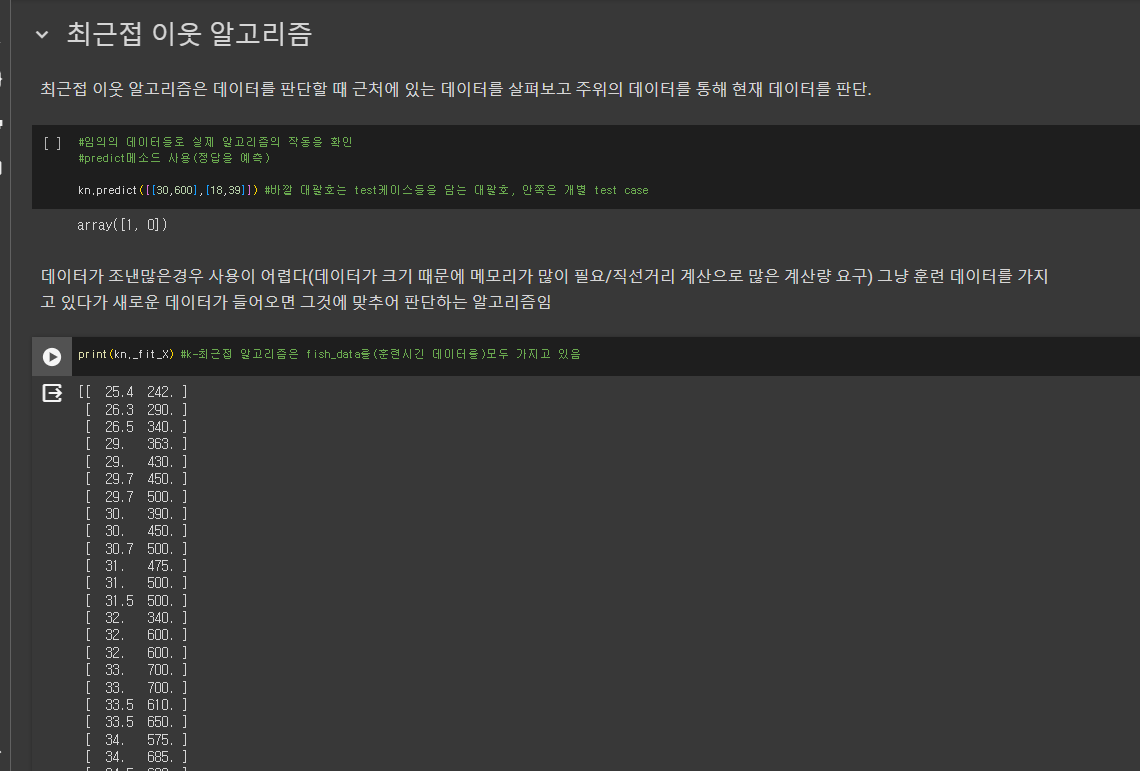

사용한 전체 코드
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0, 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0] bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0, 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0, 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0] import matplotlib.pyplot as plt # matplotlib.pyplot을 plt로 줄여서 사용.. typedef와 비슷? plt.scatter(bream_length, bream_weight) plt.xlabel("length") plt.ylabel("weight") plt.show #아래 그래프는 선형적이다. smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0] smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9] plt.scatter(bream_length, bream_weight) plt.scatter(smelt_length, smelt_weight) #scatter를 연달아 사용하면 그래프를 합칠 수 있다. plt.xlabel("length") plt.ylabel("weight") plt.show length = bream_length + smelt_length weight = bream_weight + smelt_weight #리스트 합치기 #사이킷 런 사용 -> x,y데이터를 세로로 나열한 2차원 리스트로 구성해야 함 #zip함수, 리스트 내포 구문 사용 fish_data = [[l,w] for l,w in zip(length,weight)] #zip()함수는 리스트에서 하나씩 데이터를 꺼내어 l,w에 할당 print(fish_data)#리스트 구성 확인 #위쪽 코드블럭과 이어서 코딩하려면 위쪽을 먼저 실행시켜야 함 #정답 데이터 만들기 -> bream과 smelt를 차례로 이었기 때문에 1(도미)가 35번 0(방어)가 14번 나오는 리스트를 만들어야 한다 fish_target = [1]*35 + [0]*14 print(fish_target) #사이킷런 패키지 사용 / k-최근접 이웃 알고리즘 크래스인 KNeighborsClassifier 사용 from sklearn.neighbors import KNeighborsClassifier #from ~ import구문은 특정 클래스만 import한다. kn = KNeighborsClassifier() #객체 생성 kn.fit(fish_data,fish_target) #fit 메소드는 데이터로 알고리즘을 훈련 #score 메소드는 모델 평가 메소드. 0~1 사이 값을 반환함(1은 모든 데이터를 맞춘 것을 의미 / 0은 빵개)? kn.score(fish_data, fish_target) #임의의 데이터들로 실제 알고리즘의 작동을 확인 #predict메소드 사용(정답을 예측) kn.predict([[30,600],[18,39]]) #바깥 대괄호는 test케이스들을 담는 대괄호, 안쪽은 개별 test case print(kn._fit_X) #k-최근접 알고리즘은 fish_data를(훈련시긴 데이터를)모두 가지고 있음 # 몇개의 data를 k-최근접 알고리즘은 사용하나? # 매개변수를 통해 변경할 수 있음 kn49 = KNeighborsClassifier(n_neighbors=49) #새로운 객체 생성후 매개변수 변경 kn49.fit(fish_data, fish_target) print(kn49.score(fish_data, fish_target)) print(35/49) print(35/49) #전체 생선중 도미 #코드 셀은 마지막 실행 코드의 반환값만 자동 출력. #모든 코드를 한 셀에 넣으면 중간의 반환값은 출력하지 않는다. #두 값을 모두 print해주거나 코드 셀을 나누어야 함
- matplotlib.scatter : 산점도를 표시하는 함수
- scikit-learn
- KNeighborsClassifier() : 최근접 이웃 분류 모델을 만드는 사이킷런 클래스(매개변수로 이웃의 개수 정하기. 기본값은 5)
- fit() : 모델을 훈련할 때 사용하는 메소드. 정답과 데이터를 입력.
- predict() : 훈련하고 예측할 때 사용하는 메소드
- score() : 성능 측정 # 입력 개수 대비 맞은 개수
'ML' 카테고리의 다른 글
| ML4 확률적 경사 하강법8 (0) | 2024.08.07 |
|---|---|
| ML3 / 다중회귀, 특성공학 (0) | 2024.07.28 |
| 2-1 (0) | 2024.01.29 |


